
During the past year, I wrote a 433 page technical/scientific book entitled “Bayesuvius”. Its book cover(1) is shown above. Bayesuvius was written in LaTeX, a language that is very familiar to anybody that has written a scientific or engineering paper or thesis. The LaTeX software produces a beautiful PDF. This blog post describes my saga to convert that PDF to EPUB format, in order to publish it as an ebook on Amazon.
Amazon, Barnes & Noble, Apple and several other companies allow one to self-publish a book, in either paper or ebook form or both, for free, but they charge a sales-commission fee, ka-ching, for every book sold through their website. In my case, I am not publishing in paper form, only in ebook form, and I am giving the ebook away for free, so the commission fee is of no concern to me.
I’ve chosen to make Bayesuvius a free open-source book. What I mean by this is that all the LaTeX files and a pdf compilation of it are available at github, under a Creative Commons license. If you too want to self-publish a science/technical book as an ebook, even if you don’t plan to give it away for free like me, you will still have to jump the hurdle PDF->EPUB.
If your book is already in EPUB format, self-publishing on Amazon is a very easy process. You create an account here, upload your book, answer a few questions, and presto, it shows up on their website a few days later. Millions of authors have already self-published in Amazon. Fiction writers often self-publish ebooks on Amazon and other places, and give them away for free, in order to develop a reputation and a following.
However, if your book is in PDF format and contains equations, Amazon will do an atrocious job (the result is illegible) converting it into the common ebook formats (EPUB for generic ebooks, AZW3 for Kindle/Amazon ebooks). And Barnes&Noble doesn’t even accept PDF submissions. Neither of them accepts LaTeX (most scientific publishers do).
Since my book was in PDF form, this presented a seemingly insurmountable obstacle to self-publishing. I spent a whole weekend, to no avail, trying to convert my book from LaTeX or PDF to EPUB.

I tried converting the LaTeX or PDF directly to EPUB, or, indirectly to EPUB, via an intermediate step (HTML, DOCX, RTF). I read every article I could find in Stackoverflow about converting LaTeX or PDF to HTML. HTML seemed like a promising intermediate step because EPUB is based on HTML (more precisely, the latest EPUB, v3, is based on HTML5 and is quite powerful).
I tried dozens of online document conversion sites, and when that didn’t produce a good result, I downloaded and tried the following conversion software packages. I was desperate.
- latex2html
- tex4ht/make4ht
- pandoc
- wkhtmltopdf
- prince
- calibre
- poppler-utils/pdftohtml
All yielded terrible results for my book. I’m sure those software libraries do a great job for simple pdf or latex documents, but my book is a tough customer, because it has hundreds of equations and hundreds of figures generated by complicated LaTeX packages.
Then, finally, somewhere around 2 in the morning at the end of this 2 day ordeal, the dark clouds over me lifted and my problem was solved in an instant. I found, ta-tan,
pdf2htmlEX (https://github.com/pdf2htmlEX/pdf2htmlEX)
and its experimental adjunct
pdf2epubEX (https://github.com/dodeeric/pdf2epubEX)
Check out also this github issue that alerted me to the existence of pdf2epubEX.
pdf2htmlEX and pdf2epubEx both work lighting fast. They are able to convert my whole book in less than a minute.
pdf2htmlEX produced this excellent html of my book.
pdf2epubEx also worked very fast on my book, but the resulting epub is a bit misaligned. I’ve reported the issue to its author dodeeric. I have no doubt that dodeeric and his co-workers at pdf2epubEx will be able to fix this minor misalignment issue soon. They are a brilliant bunch. They have far outwitted and outperformed the Amazon and Barnes&Noble programmers. Those 2 companies are fools not to be funding the pdf2htmlEX/pdf2epubEx organization so that it can continue developing these 2 awesome open-source tools.
I see pdf2htmlEX/pdf2epubEx as the culmination of a quest lasting at least 2 decades, to convert LaTeX to HTML (L2H). The reason it took so long is that we had to wait that long until web-browsers matured sufficiently before conversion tools could do a decent job at L2H conversion. The earliest attempts at L2H conversion, such as the latex2html software, were based on the original HTML. The original HTML was quite limited in its capabilities, by today’s standards. With it, it was impossible to generate a faithful reproduction of a LaTeX document in a webpage, unless you took a jpeg of each page. latex2html tried to convert all equations into jpeg or gif images (later attempts used mathjax) and disregarded the source’s fonts, positions of objects on the page, dimensions, etc. But once web-browsers acquired the super-powers of javascript and HTML5, all those stylistic details could be reproduced faithfully on a webpage. This table from the pdf2htmlEX website illustrates well the correlation between the evolution of web-browsers and the evolution of L2H conversion tools .
ADDENDUM (Aug 20, 2021):
dodeeric informed me that the epub being generated by pdf2htmlEX is correct. The problem is that most current ereaders, including Google’s ereader, don’t render “fixed layout” epub files correctly. I was able to find just one free ereader that does it properly. It’s called “PocketBook”.
dodeeric posted a very helpful message, in this github issue, alerting me to the existence of an Amazon format called “print replica” which can be read by the Amazon Kindle ebook reader. “It’s a format which mainly “wraps” the PDF file into another file containing metadata.” See How to prepare a print replica file from a PDF file with the Kindle Create tool
Following dodeeric’s kind advice, I downloaded Kindle Create, created a replica of my pdf, submitted it to Kindle Direct Publishing. All went through without hitting any snags. My book showed up in the Amazon website the same day. https://www.amazon.com/dp/B09D8Q4CNC/
(1) If you are curious, I created this book cover online, free of charge, using the canva.com website. I have no affiliation with canva.com. This is the first time I use their services. They were just one of the many hits that I got when I googled “design book cover online”).







 , were
, were  is the outcome for individual
is the outcome for individual  if he/she was given a treatment, and
if he/she was given a treatment, and  is the outcome if he/she was not given the treatment. Since individual
is the outcome if he/she was not given the treatment. Since individual  Time flies.
Time flies.
 states, then the probability of the system having energy
states, then the probability of the system having energy 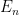 is
is  , where
, where
 Boltzmann’s constant,
Boltzmann’s constant,  temperature.
temperature. 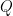 is called the partition function.
is called the partition function. as a state with energy
as a state with energy  , and
, and  as a quantum mechanical operator for a physical observable, then the expected value of the observable is
as a quantum mechanical operator for a physical observable, then the expected value of the observable is .
. clarified. We will begin by embarking on the climb.
clarified. We will begin by embarking on the climb.


