
Quantum Edward uses the BBVI training algorithm. Back Propagation, invented by Hinton, seems to be a fundamental part of most ANN (Artificial Neural Networks) training algorithms, where it is used to find gradients used to calculate the increment in the cost function during each iteration. Hence, I was very baffled, even skeptical, upon first encountering the BBVI algorithm, because it does not use back prop. The purpose of this blog post is to shed light on how BBVI can get away with this.
Before I start, let me explain what the terms “hidden (or latent) variable” and “hidden parameter” mean to AI researchers. Hidden variables are the opposite of “observed variables”. In Dustin Tran’s tutorials for Edward, he often represents observed variables by  and hidden variables by
and hidden variables by  . I will use
. I will use  instead of , so
instead of , so  below. The data consists of many samples of the observed variable . The goal is to find a probability distribution for the hidden variables . A hidden parameter is a special type of hidden variable. In the language of Bayesian networks, a hidden parameter corresponds to a root node (one without any parents) whose node probability distribution is a Kronecker delta function, so, in effect, the node only ever achieves one of its possible states.
below. The data consists of many samples of the observed variable . The goal is to find a probability distribution for the hidden variables . A hidden parameter is a special type of hidden variable. In the language of Bayesian networks, a hidden parameter corresponds to a root node (one without any parents) whose node probability distribution is a Kronecker delta function, so, in effect, the node only ever achieves one of its possible states.
Next, we compare algos that use back prop to the BBVI algo, assuming the simplest case of a single hidden parameter (normally, there is more than one hidden parameter). We will assume ![\theta\in [0, 1]](https://s0.wp.com/latex.php?latex=%5Ctheta%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000000&s=0&c=20201002) . In quantum neural nets, the hidden parameters are angles by which qubits are rotated. Such angles range over a closed interval, for example,
. In quantum neural nets, the hidden parameters are angles by which qubits are rotated. Such angles range over a closed interval, for example, ![[0, 2\pi]](https://s0.wp.com/latex.php?latex=%5B0%2C+2%5Cpi%5D&bg=ffffff&fg=000000&s=0&c=20201002) . After normalization of the angles, their ranges can be assumed, without loss of generality, to be
. After normalization of the angles, their ranges can be assumed, without loss of generality, to be ![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=000000&s=0&c=20201002) .
.
CASE1: Algorithms that use back prop.
Suppose ![\theta \in [0, 1],\;\;\eta > 0.](https://s0.wp.com/latex.php?latex=%5Ctheta+%5Cin+%5B0%2C+1%5D%2C%5C%3B%5C%3B%5Ceta+%3E+0.&bg=ffffff&fg=000000&s=0&c=20201002) Consider a cost function
Consider a cost function  and a model function
and a model function  such that
such that

If we define the change  in by
in by

then the corresponding change in the cost is

This change in the cost is negative, which is what one wants if one wants to minimize the cost.
CASE2: BBVI algo
Suppose ![\theta \in [0, 1],\;\;\eta > 0,\;\; \lambda > 0.](https://s0.wp.com/latex.php?latex=%5Ctheta+%5Cin+%5B0%2C+1%5D%2C%5C%3B%5C%3B%5Ceta+%3E+0%2C%5C%3B%5C%3B+%5Clambda+%3E+0.&bg=ffffff&fg=000000&s=0&c=20201002) Consider a reward function
Consider a reward function  (for BBVI, = ELBO), a model function , and a distance function
(for BBVI, = ELBO), a model function , and a distance function  such that
such that
![R(\lambda) = R\left[\sum_\theta dist[M(\theta), P(\theta|\lambda)]\right].](https://s0.wp.com/latex.php?latex=R%28%5Clambda%29+%3D+R%5Cleft%5B%5Csum_%5Ctheta+dist%5BM%28%5Ctheta%29%2C+P%28%5Ctheta%7C%5Clambda%29%5D%5Cright%5D.&bg=ffffff&fg=000000&s=0&c=20201002)
In the last expression,  is a conditional probability distribution. More specifically, let us assume that is the Beta distribution. Check out its Wikipedia article
is a conditional probability distribution. More specifically, let us assume that is the Beta distribution. Check out its Wikipedia article
https://en.wikipedia.org/wiki/Beta_distribution
The Beta distribution depends on two positive parameters 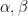 (that is why it is called the Beta distribution). are often called concentrations. Below, we will use the notation
(that is why it is called the Beta distribution). are often called concentrations. Below, we will use the notation



Using this notation,

According to the Wikipedia article for the Beta distribution, the mean value of is given in terms of its 2 concentrations by the simple expression

The variance of is given by a fairly simple expression of  and
and  too. Look it up in the Wikipedia article for the Beta distribution, if interested.
too. Look it up in the Wikipedia article for the Beta distribution, if interested.
If we define the change  in the two concentrations by
in the two concentrations by

for  , then the change in the reward function will be
, then the change in the reward function will be

This change in the reward is positive, which is what one wants if one wants to maximize the reward.
Comparison of CASE1 and CASE2
In CASE1, we need to calculate the derivative of the model with respect to the hidden parameter :

In CASE2, we do not need to calculate any derivatives at all of the model . (That is why it’s called a Black Box algo). We do have to calculate the derivative of with respect to and , but that can be done a priori since is known a priori to be the Beta distribution:
![\frac{d}{dc_j}\sum_\theta dist[M(\theta), P(\theta|\lambda)]= \sum_\theta \frac{d dist}{dP(\theta|\lambda)} \frac{dP(\theta|\lambda)}{dc_j}](https://s0.wp.com/latex.php?latex=%5Cfrac%7Bd%7D%7Bdc_j%7D%5Csum_%5Ctheta+dist%5BM%28%5Ctheta%29%2C+P%28%5Ctheta%7C%5Clambda%29%5D%3D+%5Csum_%5Ctheta+%5Cfrac%7Bd+dist%7D%7BdP%28%5Ctheta%7C%5Clambda%29%7D+%5Cfrac%7BdP%28%5Ctheta%7C%5Clambda%29%7D%7Bdc_j%7D&bg=ffffff&fg=000000&s=0&c=20201002)
So, in conclusion, in CASE1, we try to find the value of directly. In CASE2, we try to find the parameters and which describe the distribution of ‘s. For an estimate of , just use  given above.
given above.


Leave a comment