These days, I too have a hard time seeing the bright side of anything.

This is a short progress report:
JudeasRx, my proof-of-principle app for doing personalized causal medicine, can now handle more than two strata (i.e., z values, where Z is the confounder). Before, it could only handle 2 strata (male, female).
Here are some plots generated with fabricated data, for 3 and 10 strata. The next step is plugging in real data.


This is a short progress report:
JudeasRx, my proof-of-principle app for doing personalized causal medicine, now has 4 new sliders for specifying a utility function, and a new bar plot showing the bounds of the EU (expected utility).
Currently in JudeasRx, the confounder Z has only two values, m=male=blue, and f=female=pink. In real life, it’s much more common for Z to have more than 2 possible values. So the next extension I will do of JudeasRx is to allow Z to have more than 2 values.
I’ve made friends on Twitter with Boris Sobolev. Boris has informed me of a paper that he coauthored, in which Z has 64 possible values (strata). I will try to use the data in that paper as a test case for JudeasRx, once JudeasRx can handle more than two Z values. Here is an awesome plot from Boris’ paper


The purpose of this blog post is to announce that I just added a new chapter entitled “Personalized Expected Utility” (PEU) to my free open source book Bayesuvius (570 pgs). The new chapter is currently chapter 54, but this may change in the future if I add new chapters. PEU address the Unit Selection Problem (USP).
The new chapter is based on the following sources:
(Note: Pearl and Li call PEU a “benefit function”. I choose to call it a utility function to connect with the past, because it is really a utility function that we are speaking about, and utility functions have a long and illustrious history)
A second purpose of this blog post is to announce that I am currently putting the finishing touches on a Python computer program that implements Pearl-Li’s USP theory. UPDATE: JudeasRx now implements Pearl-Li’s USP theory.
Interestingly, the scientists at Uber have already added to their software library called CausalML, a “highly experimental” implementation of Pearl-Li’s USP theory. (see here, under the heading of Unit Selection). CausalML’s implementation of Pearl-Li’s USP theory seems to be a rarity for CausalML. I say this because most of CausalML is based on work by economists, and there is some bitter disagreement between some leading economists like Imbens (2021 Nobel prize in Economics for his work in CI), and Pearl (Turing prize for his work in CI). I am 99% with Pearl.
So why is this fairly technical subject of interest to anyone except me, and who else might enjoy it?
Large companies conduct what are called A/B tests. “A/B test” is another name for a RCT (Randomized Controlled Trial). It’s called an A/B test because the population is divided into 2 parts: A=control (not treated), B=treated. Then A and B are subjected to a test, and their responses recorded. Finally, a metric such as CATE (conditional average treatment effect) is calculated from the data.
PEU is a quantity which is much more discerning and all-encompassing than CATE. Whereas CATE is a metric that is based only on Experimental data (ED), PEU is based on both ED and Observational Data (OD). ED is data from an A/B test. OD is data from a survey. ED data is unconfounded. OD data is usually confounded, but it’s still useful information, because it serves to put bounds on possible PEU.
If you want to delve deeper into why I say PEU is more discerning than CATE, you can read section 8.2 of Ang Li’s thesis, entitled “8.2 Cases in which Simple A/B-test-based Approaches are not Correct .” Ang Li’s thesis has some nice examples.
Now Available at GitHub: The first version of my app for doing simple Personalized Causal Medicine via the theory invented by Judea Pearl et al. The app is called JudeasRx in honor of Judea Pearl.
https://github.com/rrtucci/JudeasRx

The last few days, I’ve been feverishly coding a “proof of concept” app for doing personalized medicine via the method envisioned by Judea Pearl. The app is called “JudeasRx” in honor of Pearl. I haven’t released the app yet, but I will do so soon. It’s already working fairly well, but I want to do a little bit more testing and polishing of the docs and code before I release it, probably in a week or two, as a free open source app. Here is a screen shot of the interface.

Programming Aspects: This photo shows the entire GUI (graphical user interface). There aren’t any other windows to the app. It’s a single window app. The app is written in Python and runs inside a Jupyter notebook. The controls that you see are coded using ipywidgets. The bar graph changes as the sliders move.
Previous work: A wonderful app that implements the same thing as JudeasRx has already been written by Scott Mueller. You can see it here. JudeasRx has a slightly different GUI.
UseCase: The app considers the simple yet illustrative case of trying to prescribe a medicine differently for male versus female patients. The Rx is based on probabilities called PNS, PN and PS that were invented by Pearl.
To do an Rx, one first allows the patients to take or not take the drug, according to their own discretion. Then one conducts a survey in which one collects info about who did or did not take the drug and whether they lived or died. This is called Observational Data (OD). Even though OD can be confounded, it serves to impose bounds on PNS, PN and PS. After the OD stage is completed, one can follow it up with a RCT (Randomized Control Experiment). In a RCT, patients must take or not take the drug as ordered by the doctor; no insubordination is tolerated. From the RCT, one collects Experimental Data (ED). The ED imposes tighter bounds on PNS, PN and PS than the bounds imposed by the OD alone.
Mathematical Theory and Notation: The mathematical theory and notation are described in gory but entertaining detail in the chapter entitled “Personalized Treatment Effects” of my book Bayesuvius. That chapter is totally based on a paper by Tian and Pearl. My only contribution(?) was to change the notation to a more “personalized” notation. In case you don’t know, Bayesuvius is my free, open source book (about 560 pages) on Bayesian Networks and Causal Inference.

You’ve probably heard the term Personalized Medicine before. It refers to methods for prescribing and even designing drugs especially targeted to the specific traits (sex, age, blood type, genetic make up, etc.) of each patient. Personalized Causal Medicine is when one uses the tools of Causal Inference (CI) to do Personalized Medicine.
How can Personalized Medicine benefit from using CI? Good question. You want to make decisions based on a RCT (randomized control trial) rather than on simple correlations, because correlations suffer from confounding. This is embodied in the maxim: “correlation does not imply causation”. On the other hand, RCT’s do imply causation. CI provides metrics such as something called ATE which measure exactly what a RCT would measure, except without having to do a RCT. RCTs are costly affairs and sometimes impossible to do. CI cleverly subtracts all confounding effects from the data in order to calculate exactly what a RCT would measure.
Personalized Causal Medicine also addresses situations in which only one, or both, of the following types of data are available: (1) information from a survey (called Observational Data, OD) (2) information from a RCT (called Experimental Data, ED). The difference between a survey and a RCT is that: in a survey, the patient is allowed to choose whether he/she takes a drug or not, whereas in a RCT, the experimenter decides, at random, which patients take the drug, and all the patients must comply with the experimenter’s choice. Unlike ED, OD might be confounded, but it still serves to impose bounds on the conditional ATE (i.e., the ATE conditioned on a trait like sex).
Over the last 20 years, Judea Pearl et al have devised a very rich set of tools for doing Personalized Causal Medicine and other types of personalized decision making. Here is a blog post, by Pearl himself, with links to all the most pertinent original references. Pearl often suggests in his Tweets that his personalized CI theory could be the foundation of a billion dollar industry. I enthusiastically agree.
I’m happy to announce that Bayesuvius now has a chapter entitled “Personalized Treatment Effects” explaining Pearl’s personalized CI theory. It’s currently chapter 53, but that may change in future editions of Bayesuvius. In case you don’t know, Bayesuvius is my free, open source book (about 560 pages) on Bayesian Networks and Causal Inference.


Anytime one uses Statistics, there is a danger of selection bias (SB), so SB is as ubiquitous as the use of Statistics itself. If you look at the SB entry in Wikipedia, you will see that people have identified numerous flavors of SB, but they all boil down to the same thing: sampling from an atypical subset of a population.
Experimentalists in all the sciences put a lot of effort into avoiding SB. But if they discover that their data has SB, does this mean they have to discard it? Not necessarily. Sometimes it is possible to add more data to the original data so that the new, enhanced dataset is no longer biased. It’s like making horizontal the surface of a table that was not initially horizontal. Bareinboim, Tian and Pearl wrote a paper in 2014 that uses Bayesian Networks and Causal Inference to remove SB from a dataset. I dug up the 2014 reference and upon reading it, I decided it was very cool and that I should write a chapter about it for my book Bayesuvius. The first version of that Bayesuvius chapter on “Selection Bias Removal” is now available. It’s currently chapter 63, but that may vary in future editions of Bayesuvius. In case you don’t know, Bayesuvius is my free, open source book (530 pages) on Bayesian Networks and Causal Inference.
There are many good stories on the internet about the importance of not ignoring SB. One of the most famous and instructive ones is the one about damage in WW2 bombers. Here is that story as told by Wikipedia:
During World War II, the statistician Abraham Wald took survivorship bias into his calculations when considering how to minimize bomber losses to enemy fire.[11] The Statistical Research Group (SRG) at Columbia University, which Wald was a part of, examined the damage done to aircraft that had returned from missions and recommended adding armor to the areas that showed the least damage. This contradicted the US military’s conclusion that the most-hit areas of the plane needed additional armor.[12][13][14] Wald noted that the military only considered the aircraft that had survived their missions – ignoring any bombers that had been shot down or otherwise lost, and thus also been rendered unavailable for assessment. The bullet holes in the returning aircraft represented areas where a bomber could take damage and still fly well enough to return safely to base. Therefore, Wald proposed that the Navy reinforce areas where the returning aircraft were unscathed,[11]: 88 inferring that planes hit in those areas were the ones most likely to be lost. His work is considered seminal in the then-nascent discipline of operational research.[15]

(from Wikipedia) The damaged portions of returning planes show locations where they can sustain damage and still return home; those hit in other places presumably do not survive. (Image shows hypothetical data.)
Instrumental Variables (IVs) are an important tool in Causal Inference—a tool often used by economists in their studies of causal effects. My book Bayesuvius has a chapter on IVs. Here is how they work, from a baby perspective.

(Photo of Piscina Mirabilis, an ancient Roman cistern in Naples)
In a recent blog post, I pointed out a recent paper with 19 authors from Google’s DeepMind, that uses extensively Judea Pearl’s Causal Inference theory. I found out about that paper from a tweet by Judea Pearl himself. In his tweets about that Googlian paper, Pearl advised the authors to look at his 1995 paper with Robins about “sequential backdoor” identification. I dug up the 1995 reference and upon reading it, I decided it was very cool and that I should write a chapter about it for my book Bayesuvius. The first version of that Bayesuvius chapter on sequential backdoors is now available. It’s currently chapter 64, but that may vary in future editions of Bayesuvius. In case you don’t know, Bayesuvius is my free, open source book (530 pages) on Bayesian Networks and Causal Inference.
So why do I think sequential backdoor identification is important? When doing Reinforcement Learning (a type of dynamic Bayesian network), it is highly desirable that the agent make decisions based on 
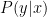


If an agent remembers more than one past time slice, the question arises, HOW does one “identify” (i.e., calculate from the observed data alone, not from info about unobserved nodes) queries with multiple do’s. A related question that arises is WHEN is it possible to identify queries with multiple do’s.
Check out this hilarious article
https://venturebeat.com/2021/11/01/multiverse-computing-utilizes-quantum-tools-for-finance-apps/
The first two lines took my breath away
Despite great efforts to unseat it, Microsoft Excel remains the go-to analytics interface in most industries — even in the relatively tech-advanced area of finance.
Could this familiar spreadsheet be the portal to futuristic quantum computing in finance? The answer is “yes,” according to the principals at Multiverse Computing.
And shortly after that article appeared, IonQ tweeted this declaration of love

IonQ is promising to everyone a quantum advantage in financial applications in 3 years.
Do you think the ionQ/Multiverse juggernaut will sweep Wall Street with their Excel application in 3 years? I have my doubts. If it were a Cobol application, then I might believe it, but Excel? 🙂 If Excel is so great for quantum computing, don’t you think that Microsoft, which has been doing qc for 20 years, would have used it in their Q# quantum software long ago? For IonQ to endorse so strongly an obvious snake oil salesman like MultiverseQC, should give IonQ investors pause. I have found the saying “Birds of a feather hang together” to be very true throughout my life.
Even if we ignore the funny fact that IonQ’s quantum computers run on Excel spreadsheets, can ionQ really achieve a quantum advantage in financial applications in 3 years? Even Zillow, with a large AI team and a Kaggle contest to get the best predictions from AI, got catastrophically bad advice from the latest AI. The best investors, like Warren Buffet, use their deep knowledge and understanding of the markets to invest. They don’t give a hoot about what software models predict. They might look at the software predictions and decide they are crap and go with their instincts, instincts which they have honed over dozens of years.
Check out
Shaking the foundations: delusions in sequence models for interaction and control
https://arxiv.org/abs/2110.10819, by 19 DeepMind authors
The phrase “Shaking the foundations” refers to Foundation Models such as BERT (another Google creation).
I recently wrote a blog post arguing that Foundation Models are a dead end street and poor foundation for AI; they should be replaced, at least for certain tasks, by something much better: Causal Inference. This paper seems headed in that direction.

Real Scientists almost never fit data without a prior model/hypothesis. Only AI rubes do that. Scientists almost always follow the scientific method which says, (1) guess the model/hypothesis (2) find curve predicted by model (3) fit data with predicted curve.
The word “rube” has an interesting etymology. It’s a nickname for Reuben, which is a Jewish name that appears in the Bible. Rube Goldberg was actually a Reuben Goldberg.



