
When conducting an experiment to try to decide whether a medical treatment (or a marketing gimmick or a business decision) is being, or will be, effective, one must try to find out what external variables might be confounding the data. These confounders are also called controls. The problem with controls is that they are not all created equal. Controlling the value of a control in an experiment might clarify, or it might hide, the answer to the question of whether the treatment is effective, or not. Judea Pearl et al wrote last year a wonderful paper
in which he explains his method for deciding which controls are good to control and which aren’t. He addresses this question using DAGs (directed acyclic graphs), and his theory of causal inference (CI).
The above paper considers 20 DAGs. The purpose of this blog post is to announce that I have analyzed those 20 DAGs using the “Identifiability Checker” of my free, open source software JudeasRx. The results of that analysis are contained in the following Jupyter notebooks.
- drawings
- 1-4
- 5-8
- 9-11u
- 12-15
- 16-18
- 7up
- SUMMARY
I’ve translated each of those 20 DAGs into its own Dot File. I’ve also started a new JudeasRx folder called “dot_atlas” .My “dot_atlas” is devoted to holding just DAGs in the dot file format. I imagine humans all carry a personal dot_atlas in their head. This reminds me of the excellent novel and movie “Cloud Atlas…Everything is connected”. (In case you don’t know, a dot file is a txt file that contains a description of a DAG. Dot files can be drawn using a rendering engine called graphviz. graphviz is the preferred DAG rendering engine for JudeasRx.)
Final advice for those suffering from DAG-phobia or DAG-aversion:
DAGs are your friends. DAGs should be easy and fun to dream up. After all, I am convinced that DAGs are an integral part of how humans think, so they should come naturally to us. Nevertheless, many people are scared of, or detest, DAGs. I think it’s because they fail to grasp the following 3 things:
1. DAGs are not unique. Stop thinking that you have to find the unique DAG for the situation being considered. You just have to find a DAG that is a good causal fit for the situation. If a DAG is too complicated, you can always simplify it by merging several nodes into a single more abstract one, or by summing over unwanted nodes.
2. DAGs are roughly ordered from past to present. The arrows of a DAG roughly reflect the passage of time.
3. DAGs represent a scientific hypothesis that can and should be tested with do experiments.







 is said to be Pearl identifiable within the context of a bnet (Bayesian network) G iff one can calculate a precise value for
is said to be Pearl identifiable within the context of a bnet (Bayesian network) G iff one can calculate a precise value for 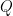 . This is always possible if G does not contain any unobserved nodes. If G does contain unobserved nodes, one can always find bounds for
. This is always possible if G does not contain any unobserved nodes. If G does contain unobserved nodes, one can always find bounds for  and an arrow
and an arrow  . Assume we are also given the TPMs (Transition Probability matrices) of all nodes except for the unobserved nodes.
. Assume we are also given the TPMs (Transition Probability matrices) of all nodes except for the unobserved nodes.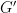 from bnet
from bnet  by removing from
by removing from  .
.
 Y) , an approximation technique known as Gibbs sampling can be used (Robert and Casella 1999). A graphical version of this technique, called “stochastic simulation,” is described in Pearl (1988b, p. 210); the details (as applied to the graph of Figure 8.4) are discussed in Chickering and Pearl (1997). Here we present typical results,in the form of histograms, that demonstrate the general applicability of this technique to
Y) , an approximation technique known as Gibbs sampling can be used (Robert and Casella 1999). A graphical version of this technique, called “stochastic simulation,” is described in Pearl (1988b, p. 210); the details (as applied to the graph of Figure 8.4) are discussed in Chickering and Pearl (1997). Here we present typical results,in the form of histograms, that demonstrate the general applicability of this technique to . I can understand the definitions well enough, but I have a hard time remembering which symbol stands for what. So I came up with a mnemonic for the 3 most common types of Big-O notations. I decided it looks like a bald, bow-legged, fat person with a belt.
. I can understand the definitions well enough, but I have a hard time remembering which symbol stands for what. So I came up with a mnemonic for the 3 most common types of Big-O notations. I decided it looks like a bald, bow-legged, fat person with a belt.

